
{kind=link}
As a subject and consulting engineer, I’ve witnessed the evolution of information heart applied sciences firsthand, from conventional bare-metal server deployments and virtualized cluster environments to the rising calls for on storage and the convergence of compute and storage. My expertise with hyperconverged environments utilizing Cisco and Nutanix HCI options has led me to appreciate that we’d like a brand new definition.
HCI often stands for “hyper-converged infrastructure.” However do we actually perceive the true essence and affect of the expertise? HCI radically adjustments information heart structure by eliminating centralized community storage and consolidating storage and compute sources right into a single normal server node. The nodes are clustered, virtualized, and overlaid with distributed HCI software program that abstracts and aggregates the capability of all nodes right into a shared useful resource pool.
After all, all sources are software-defined and managed by way of a easy Net UI. The result’s a drastic simplification of the information heart structure, elevated utilization and effectivity via greater consolidation, the flexibility to outline storage properties per VM disk, decrease complete value of possession, and so on.
However there’s far more to HCI than useful resource consolidation and administration simplification supplied by Cisco UCS-X modular methods, Intersight cloud-management, and future-proof Nutanix HCI structure. We argue that HCI ought to stand for “hybrid cloud infrastructure!” Let’s discover the 5 underlying, much less apparent, however future-impacting HCI design cues.
1. Incremental storage capability enlargement
Think about not having 70 % of storage go unused (wasted) for the primary three years.
HCI essentially adjustments the way in which you handle your information heart development. We historically buy storage methods that final greater than 5 years. Plus, we at all times add buffer capability margins, simply in case. Because of this, the storage system is extraordinarily underutilized initially.
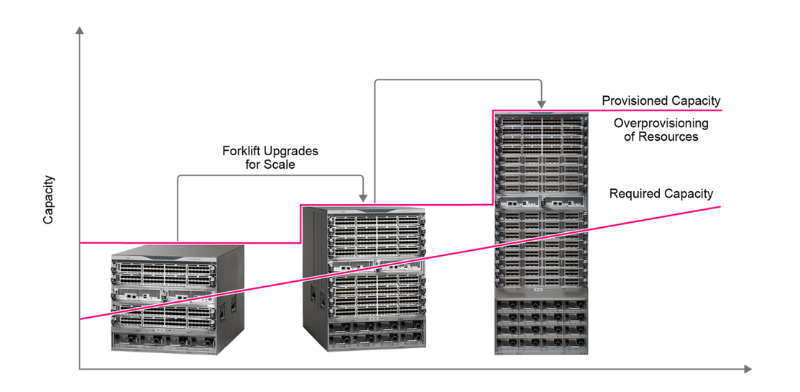
So, as an alternative of shopping for upfront many sources that slowly (if ever) get absolutely utilized, you’ll be able to optimally increase your infrastructure footprint by shopping for what you really want (a capability node or a efficiency storage node) once you really need it. This manner you keep away from relying in your magic ball and get rid of forklift upgrades. Basically, you’re losing fewer sources by avoiding overprovisioning of idle capability on Day 1.
Enjoyable reality: Nutanix (as of not too long ago) additionally helps including exterior third-party storage methods, corresponding to these from Everpure.
2. Software program-defined infrastructure at all times evolves
Are you aware concerning the information heart Fountain of Youth? Your current infrastructure cluster can get higher over time!
Shifting superior options processing (information effectivity and tiering, community features, safety mechanisms, and so on.) to software program allows your HCI stack to remain in form by counting on over-the-air upgrades for brand spanking new options, {hardware} compatibility, and safety posture.
It’s not nearly options. With this method, you too can enhance your information heart efficiency by receiving HCI software program stack optimization patches*. This course of is much like how one can unlock further engine energy with a easy over-the-air software program replace in fashionable automobiles.
3. Heterogeneous (disaggregated) {hardware} methods
Everyone knows {that a} motherboard or energy failure will take down all servers’ sources (CPU, RAM, storage) with it. However do you know it doesn’t need to be this fashion?
Whereas the whole lot is getting software-defined, on the identical time we’re witnessing the rise of domain-specific {hardware} accelerators corresponding to the information processing unit (DPU) and even application-specific processors (due to the RISC-V open structure) to hurry up particular workload processing and bounce over the Moore’s Legislation pace bump that’s forward of us.
Other than accelerators, we now have a development towards absolutely decoupled {hardware} methods, with devoted resource-specific {hardware} nodes: compute, reminiscence, and storage nodes. Useful resource-specific nodes are aggregated into useful resource swimming pools. Heterogeneous {hardware} methods are enabled with mechanisms corresponding to Compute Specific Hyperlink (CXL) with which CPUs and accelerators share reminiscence and cache coherently. Reminiscence may be connected as a shared, fabric-accessible useful resource slightly than being stranded on particular person servers.
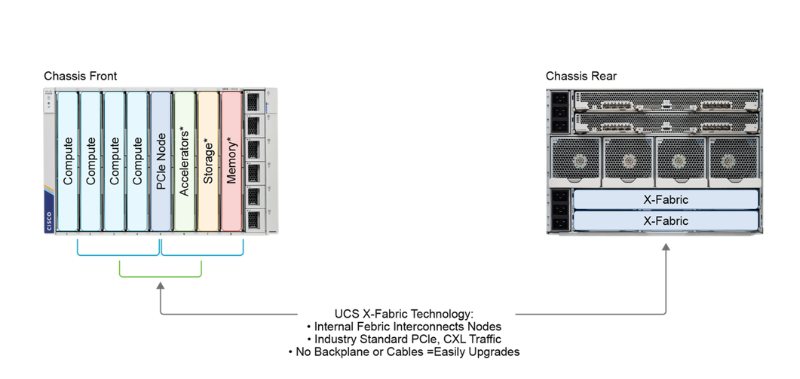
The reasoning right here is that when upgrading, we’d not want extra CPU—simply extra RAM capability or extra storage. So, you’ll be able to improve your infrastructure extra optimally with out buying sources you don’t want.
This disaggregated {hardware} method additionally essentially adjustments your information heart operations and reliability. B separating particular sources into devoted nodes, we create smaller failure domains. As an example, CPU failure won’t take storage and RAM sources down with it.
We have already got components of this disaggregated {hardware} with UCS-X structure, which (in addition to common compute nodes) gives storage nodes and decoupled scalable networking with UCS-X Cloth. You’ll find your optimum X-Sequence node right here. And who is aware of what the long run holds? Consider superior networking with optical switching, future devoted nodes with domain-specific accelerators, and extra!
Be aware: For extra particulars, go to Cisco Compute Hyperconverged X-Sequence System with Nutanix.
4. Evolvable infrastructure
Gmail has been working steadily for over 20 years. Are you able to think about what number of instances Google has utterly changed the underlying infrastructure with out ever inflicting software service downtime?
Hyperscalers have been utilizing HCI-like infrastructure for many years (together with compute/storage/community useful resource pooling and horizontal scaling) with their very own inside stacks and tooling. Moreover, to turbo-charge their HCI answer, they rely closely on customized {hardware}/software program co-design (customized offloads for networking and storage processing). And naturally, by way of configuration and administration, the whole lot is software-defined.
If we consider hyperscalers as F1 automobiles (serving as R&D platforms) and our enterprise information facilities as common, on a regular basis automobiles, we are able to surmise that this modern structure is sure to trickle all the way down to our enterprise information facilities.

HCI allows an evolvable infrastructure that forestalls you from having to throw something away. Slightly, it step by step upgrades your cluster with newer nodes. It’s wonderful to combine nodes with various efficiency and capability ranges, like grooming a plant ecosystem by step by step replenishing your backyard. Ultimately, you’ll take away some nodes from the cluster (when a node dies as a consequence of age otherwise you resolve to repurpose it after about 10 years to a testing cluster), however it will usually occur a lot later than with our present (~5-year) improve cycle. So primarily, you’ll get extra time and sources out of your useful funding whereas being extra eco-friendly!
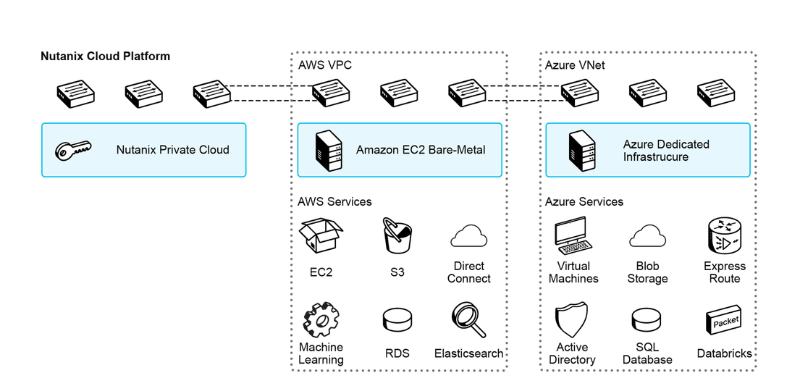
5. Plug your HCI cluster into public clouds
Yet one more factor: after you have your cloud on the bottom, powered by Hyperscalers’ DNA, you’ll be able to extra simply plug it right into a hyperscale cloud. It’s not advertising fluff; it’s an actual product. For instance, Nutanix Clusters means that you can run 100% native Nutanix HCI on rented bare-metal servers of AWS, Azure, and GCP.
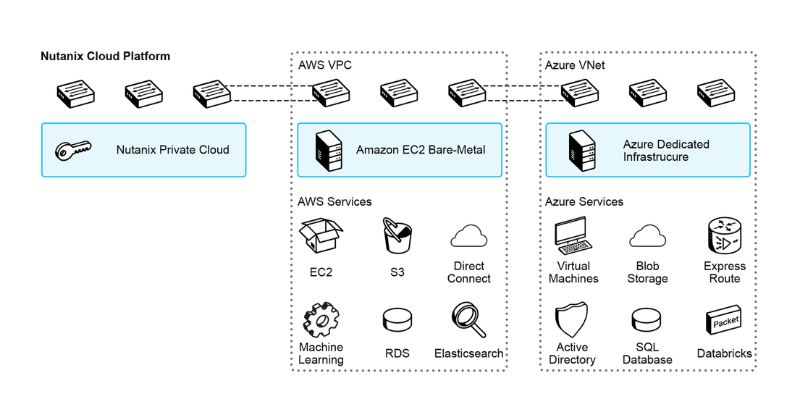
This manner, you’re switching to an OPEX mannequin by renting each the {hardware} and the software program license. Moreover, Nutanix Clusters unlock the next options:
- A single pane of glass to handle each on-prem and cloud-based infrastructure footprints
- Capability emigrate your purposes between on-prem and cloud environments with out worrying about foolish particulars corresponding to disk codecs
- Even your networking constructs (Digital Community in Nutanix, VPC/VNET in Hyperscalers) are normalized, i.e., translated mechanically
Take a look at Nutanix now
So, would you like a take a look at drive? There’s no must schedule (and no driving license wanted). Simply your electronic mail handle: Take a fast Nutanix Take a look at Drive.
To remain tuned, observe our NIL Studying Information Library or watch the Cisco Reside session about this matter:
For extra common particulars about Cisco & Nutanix Options, go to this web page. To search out out extra about Cisco and Nutanix collaboration, learn: The following chapter of Cisco and Nutanix: Constructing versatile infrastructure for the fashionable period.
And lastly, if you’re nonetheless evaluating or already implementing HCI and wish professional coaching, you’ll be able to take a look at our current coaching providing or attain out to us if you want one thing totally different (LS_Sales_Support@nil.com). Our workforce has 33 years of expertise creating and delivering IT coaching and huge expertise in deploying information heart and HCI methods.
*For instance, Nutanix AOS 5.20 provided vital efficiency boosts, primarily via smarter Oplog dealing with for higher sequential writes (doubling efficiency in some circumstances) and vDisk sharding, which dramatically improved random learn efficiency (as much as 172% acquire) and database transaction charges (as much as 78% acquire) by optimizing CPU utilization for small I/O. And this was supplied freed from cost to all current customers by way of a easy over-the-air replace!
Learn subsequent: